



ساخت RAG Chatbot
در این راهنما، خواهید آموخت که چگونه میتوانید یک برنامه چتبات مبتنی بر RAG (یا Retrieval-Augmented Generation)، ایجاد کنید.
قبل از آنکه وارد جزئیات شویم، بیایید ببینیم RAG چیست و چرا ممکن است بخواهیم از آن استفاده کنیم.
RAG چیست؟
RAG مخفف عبارت Retrieval-Augmented Generation (یا تولید مبتنیبر بازیابی)، است. به زبان ساده، RAG فرآیند ارائه LLM با اطلاعات مشخص و مرتبط با پرامپت ورودی، میباشد.
چرا RAG مهم است؟
با وجود اینکه LLMها، قدرتمند هستند، اما توانایی آنها در استدلال، فقط محدود به دادههایی است که بر روی آنها، آموزش دیدهاند. این محدودیت، زمانی نمایان میشود که از یک LLM اطلاعاتی درخواست شود که خارج از دادههای آموزشی آن است؛ مانند دادههای اختصاصی (در یک شرکت) یا اطلاعات عمومی که پس از تاریخ اتمام آموزش مدل، بهوجود آمدهاند. RAG این مشکل را حل میکند؛ به این صورت که ابتدا اطلاعات مرتبط با پرامپت را بازیابی کرده و سپس آن را بهعنوان context در اختیار مدل، قرار میدهد.
بهعنوان مثال، فرض کنید که از مدل میپرسید "غذای مورد علاقه من چیست؟". پاسخ مدل، احتمالاً مشابه زیر، خواهد بود:
جای تعجب نیست که مدل پاسخ این سؤال را نمیداند. اما فرض کنید که همراه با پرامپت شما، مدل، مقداری context اضافی نیز، دریافت کند:
به همین سادگی، شما فرآیند تولید مدل را با ارائه اطلاعات مرتبط با پرسش، تقویت کردهاید. اگر مدل به اطلاعات مناسب دسترسی داشته باشد، احتمال زیادی وجود دارد که پاسخ دقیقی به پرسش کاربر، ارائه دهد.
اما سؤال اینجاست: چگونه مدل این اطلاعات مرتبط را بازیابی میکند؟ پاسخ در مفهومی به نام Embedding، نهفته است.
شما میتوانید از هر منبعی برای فراهم کردن context در برنامه RAG خود استفاده کنید (برای مثال، جستجوی گوگل). Embeddings و پایگاهدادههای برداری (Vector Databasها) تنها یکی از روشهای خاص بازیابی اطلاعات هستند که برای رسیدن به جستجوی معنایی (Semantic Search) بهکار میروند.
Embedding
Embedding یا بردارسازی، روشی است برای نمایش کلمات، عبارات یا تصاویر، بهصورت بردارهایی در فضایی با ابعاد بالا (High-Dimensional Space). در این فضا، واژههای مشابه از نظر معنایی، به یکدیگر نزدیک هستند و فاصله بین این کلمات، راهی برای اندازهگیری شباهت آنها است.
در عمل، اگر شما کلمات "گربه" و "سگ" را بردارسازی کنید، انتظار دارید که در فضای برداری، در نزدیکی هم ترسیم شوند. فرآیند محاسبه شباهت بین دو بردار، شباهت کسینوسی (Cosine Similarity) نام دارد؛ که در آن، مقدار 1 نشاندهنده شباهت بسیار بالا، و مقدار 1- نشاندهنده تضاد کامل بین دو بردار است.
اگر این مفاهیم در ابتدا پیچیده به نظر میرسند، نیازی به نگرانی نیست. درک کلی و انتزاعی موضوع، برای شروع کاملاً کافی است.
همانطور که قبلتر اشاره شد، بردارسازی روشی است برای نمایش معنای مفهومی (semantic meaning) کلمات و عبارات. نکتهی مهم این است که هرچه ورودی بردارساز، بزرگتر باشد، کیفیت بردار تولیدشده ممکن است پایینتر بیاید. اکنون، سوال اصلی این است که چگونه میتوانید محتوایی را که از یک عبارت ساده، خیلی طولانیتر است، به بردار تبدیل کنید؟
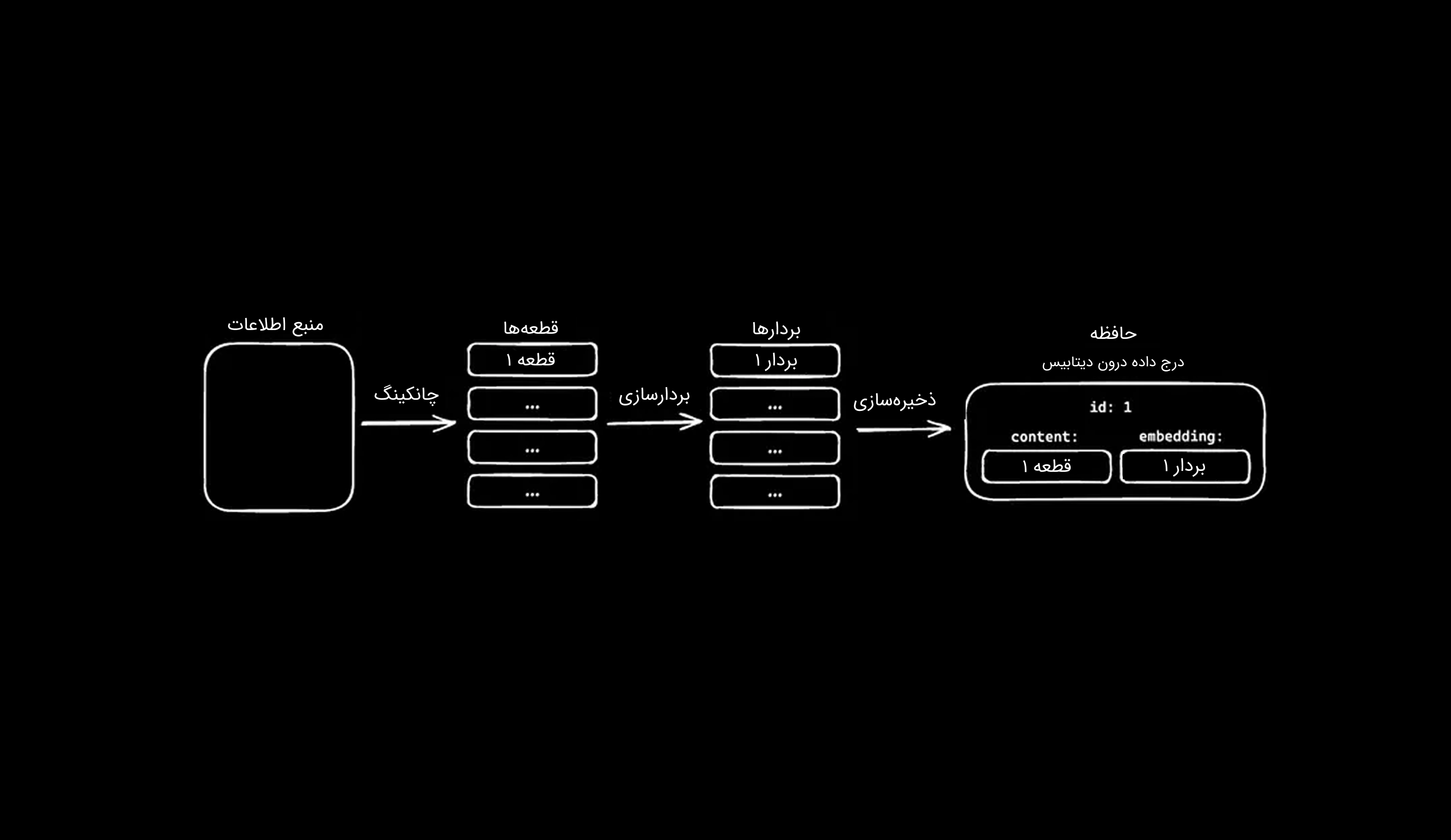
Chunking
Chunking یا تکهتکهسازی، فرآیندی است که در آن، یک منبع اطلاعاتی به بخشهای کوچکتر، تقسیم میشود. روشهای مختلفی برای انجام این کار وجود دارد و پیشنهاد میشود که بسته به نوع پروژه، فرایندهای Chunking متفاوتی را آزمایش و مقایسه کنید، چرا که بهترین روش، با توجه به use case شما، میتواند متفاوت باشد. یکی از روشهای ساده و رایج در Chunking (و روشی که در این راهنما از آن استفاده خواهید کرد)، تقسیم محتوای متنی بر اساس جملات است.
پس از آنکه منبع شما، بهدرستی قطعهقطعه شد، میتوانید هر قطعه را بردارسازی کرده و سپس بردار بهدستآمده را بههمراه محتوای همان قطعه، در یک پایگاهداده ذخیره کنید. بردارها را میتوان در هر پایگاهدادهای که از vectorها پشتیبانی میکند ذخیره کرد. در این آموزش، از Postgres بههمراه افزونهی pgvector استفاده خواهید کرد.
همهچیز در کنار هم
با کنار هم قرار دادن تمام این موارد، میتوان گفت که RAG فرآیندی است که در آن، مدل میتواند به اطلاعاتی فراتر از دادههای آموزشی خود پاسخ دهد؛ این کار با بردارسازی پرسش کاربر، بازیابی قطعههایی از منبع اطلاعاتی (چانکها) که بیشترین شباهت معنایی را دارند، و سپس ارسال آنها بههمراه پرامپت اولیه به مدل بهعنوان context، انجام میشود. اگر به مثال قبلی بازگردیم، یعنی زمانی که از مدل میپرسید "غذای مورد علاقه من چیه؟"، فرآیند آمادهسازی پرامپت به این صورت خواهد بود:
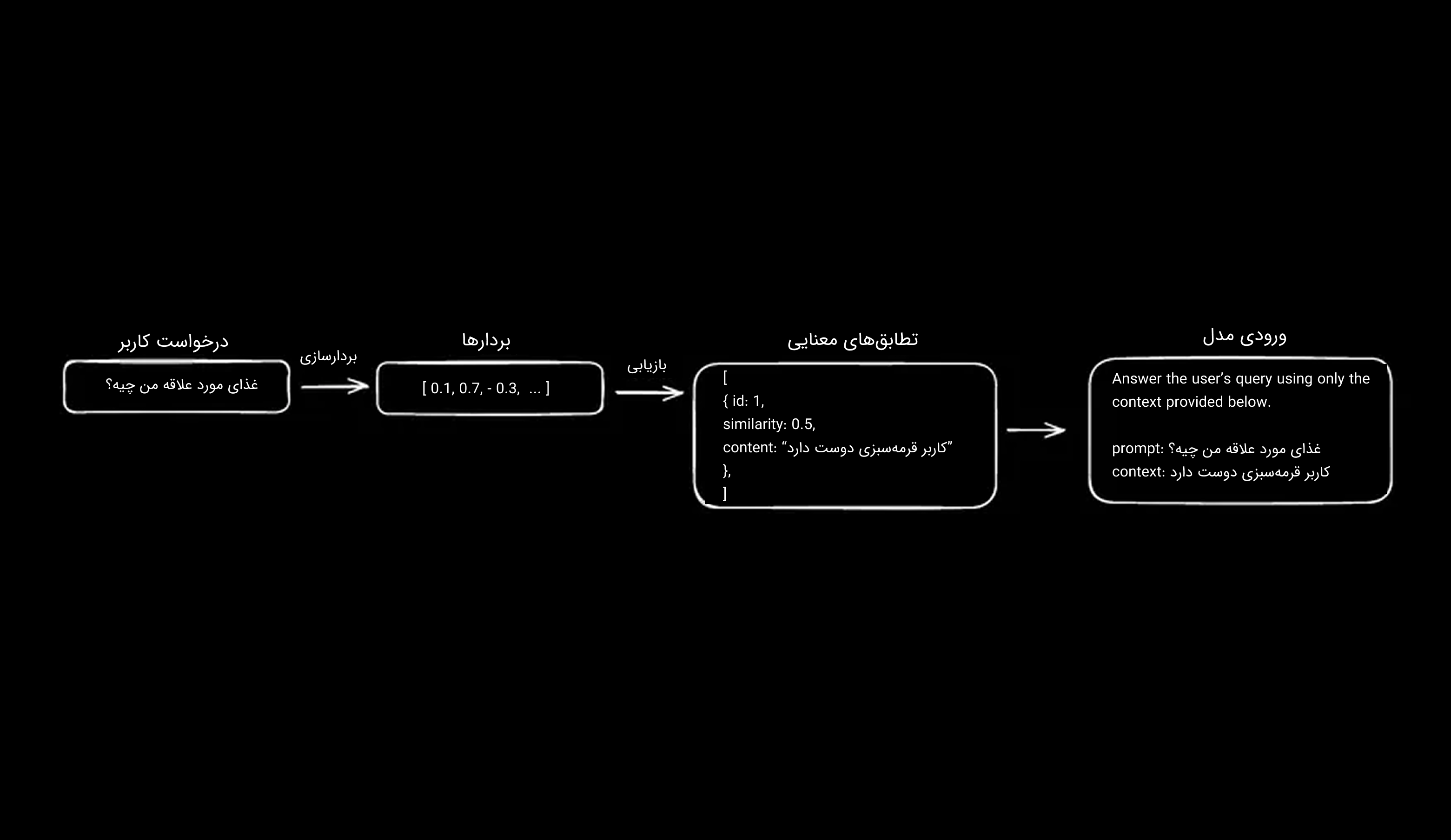
با ارائه context مناسب و تنظیم هدف مدل بهدرستی، میتوانید بهخوبی از توانایی آن بهعنوان یک ماشین استدلالگر (reasoning machine) بهرهمند شوید.
راهاندازی پروژه
در این پروژه، شما یک چتبات خواهید ساخت که تنها با استفاده از اطلاعات موجود در پایگاه دانش خود پاسخ میدهد. این چتبات قابلیت ذخیرهسازی و بازیابی اطلاعات را خواهد داشت و کاربردهای جالبی دارد، از پشتیبانی مشتریان گرفته تا ساختن یک نسخه دیجیتالی از "ذهن دوم" خودتان.
فناوریهای استفادهشده در این پروژه، عبارتند از:
- فریمورک NextJS
- ماژول AI SDK
- API هوش مصنوعی لیارا
- Drizzle ORM
- دیتابیس Postgres به همراه pgvector
- ماژول shadcn-ui و TailwindCSS برای استایلدهی
کلون ریپازیتوری
برای سادهتر کردن این آموزش، از یک ریپازیتوری آماده استفاده میکنیم که برخی از تنظیمات اولیه را از قبل دارد:
- Drizzle ORM (دایرکتوری lib/db) شامل یک migration اولیه و یک اسکریپت برای انجام migrate (db:migrate)
- یک schema ساده برای جدول resources (این جدول برای منبع اطلاعات یا همان source material بهکار خواهد رفت)
- یک Server Action برای ایجاد منبع (resource)
برای شروع، ابتدا ریپازیتوری اولیه را با دستور زیر کلون کنید:
در مرحله اول، برای نصب وابستگیهای پروژه، دستور زیر را اجرا کنید:
ایجاد دیتابیس
برای تکمیل این آموزش، به یک پایگاهداده Postgres نیاز دارید. اگر Postgres روی سیستمتان نصب نیست، میتوانید با دنبالکردن این راهنما، اقدام به نصب Postgres بر روی سیستم خود کنید.
migrate دیتابیس
پس از ساخت دیتابیس، باید connection string آن را بهعنوان متغیر محیطی، به برنامه اضافه کنید. برای این کار، با اجرای دستور زیر (در لینوکس)، یک کپی از فایل env.example. ایجاد کنید و نام آن را به env. تغییر دهید:
یا اینکه، بهسادگی نام فایل env.example. را به env. تغییر دهید. در ادامه، فایل env. جدید را باز کنید. باید متغیری را با نام DATABASE_URL مشاهده کنید. connection string دیتابیس خود را پس از علامت مساوی (=) در این قسمت، قرار دهید. با انجام کارهای فوق، اکنون میتوانید اولین migration دیتابیس را اجرا کنید. دستور زیر را اجرا نمایید:
دستور فوق، ابتدا افزونهی pgvector را به دیتابیس شما اضافه میکند. سپس یک جدول جدید برای اسکیمای resources ایجاد خواهد کرد که در فایل lib/db/schema/resources.ts تعریف شده است. این اسکیما شامل چهار ستون id، content، createdAt و updatedAt است.
اگر هنگام اجرای migration با خطا مواجه شدید، فایل migration خود را باز کنید (lib/db/migrations/0000_yielding_bloodaxe.sql)، خط اول آن را cut کنید (کپی کرده و سپس حذف کنید)، و آن خط را مستقیماً روی instance دیتابیس PostgreSQL خود، اجرا نمایید. اکنون، میتوانید migration بهروزشده را اجرا کنید.
baseUrl و کلید API لیارا
برای استفاده از این راهنما، در ابتدا باید، محصول هوش مصنوعی لیارا را تهیه کنید. البته میتوانید از کلید خریداری شده OpenAI نیز استفاده کنید. در صورتی که قصد دارید مدل خود را از لیارا تهیه کنید؛ تنها به baseUrl محصول هوش مصنوعی لیارا و کلید API کنسول خود نیاز دارید.
ساخت (build)
بیایید یک فهرست از کارهایی که باید انجام شوند تهیه کنیم:
- ایجاد یک جدول در دیتابیس برای ذخیرهی embeddingها
- افزودن منطق chunking و ایجاد embeddingها هنگام ساخت resources
- ایجاد یک چتبات
- اتصال چتبات به toolهایی برای جستجو و ایجاد resources برای پایگاه دانش آن
ایجاد جدول Embeddings
در حال حاضر، برنامهی شما دارای یک جدول به نام resources است که یک ستون به نام content برای ذخیرهی محتوا دارد. هر منبع (منبع اولیهی اطلاعات) باید به قطعههایی تقسیم شود؛ embedding آن تولید گردد و سپس ذخیره شود. در این مرحله، باید یک جدول به نام embeddings برای ذخیرهی این قطعهها ایجاد کنیم.
یک فایل جدید به نام lib/db/schema/embeddings.ts ایجاد کرده و کد زیر را به آن اضافه کنید:
این جدول شامل چهار ستون است:
- id: شناسهی یکتا
- resourceId: کلید خارجی که به منبع کامل اطلاعات اشاره میکند
- content: قطعه متنی (chunk) ساده شده
- embedding: نمایش برداری (وکتوری) از بخش متنی سادهشده
برای انجام جستجوی شباهت (similarity search)، همچنین باید یک ایندکس (از نوع HNSW یا IVFFlat) بر روی ستون embedding ایجاد کنید تا عملکرد بهتری داشته باشید. برای اعمال تغییرات در دیتابیس، دستور زیر را اجرا کنید:
افزودن منطق Embedding
اکنون که یک جدول برای ذخیرهی embeddingها دارید، نوبت نوشتن منطق لازم برای ایجاد embeddingها است. برای این کار، ابتدا با استفاده از دستور زیر (در لینوکس)، فایل موردنیاز را ایجاد کنید:
یا اینکه کافیست به سادگی، در دایرکتوری lib، یک دایرکتوری جدید به نام ai ایجاد کنید و سپس یک فایل جدید به نام embedding.ts در آن دایرکتوری بسازید.
تولید chunkها
برای ایجاد یک embedding، ابتدا باید یک قطعه از منبع اطلاعاتی (با طول نامشخص) را گرفته و سپس آن را به قطعههای کوچکتر تقسیم کنید، در ادامه، روی هر قطعه، بردارسازی کنید و سپس هر قطعه را در دیتابیس، ذخیره نمایید. بیایید با ساخت تابعی برای تقسیم محتوای منبع به قطعههای کوچک، شروع کنیم: در مسیر lib/ai/embedding.ts قطعه کد زیر را قرار دهید:
تابع فوق، یک رشتهی متنی را بهعنوان ورودی میگیرد و جملات درون آن را با استفاده از نقطه (.)، از هم جدا میکند. سپس، هر عضو خالی آرایه را حذف میکند و در نهایت، آرایهای از رشتههای متنی برمیگرداند. لازم به ذکر است که در پروژههای مختلف، تکنیکهای chunking متفاوت، ممکن است عملکرد بهتری داشته باشند، بنابراین آزمایش با روشهای گوناگون پیشنهاد میشود.
نصب AI SDK
برای ایجاد embeddingها از AI SDK استفاده خواهیم کرد. این کار به چند ماژول اضافی نیاز دارد. برای نصب آنها، دستور زیر را اجرا کنید:
دستور فوق، AI SDK، هوکهای @ai-sdk/react و @ai-sdk/openai (برای اتصال به مدل) را به پروژهی شما اضافه میکند.
با AI SDK و محصول هوش مصنوعی لیارا، شما میتوانید به LLMهای متنوع و متفاوتی دسترسی داشته باشید؛ آن هم تنها با یک خط تغییر در کد.
تولید embeddingها
بیایید تابعی برای تولید embeddingها اضافه کنیم. کد زیر را در فایل lib/ai/embedding.ts خود قرار دهید:
در قطعه کد فوق، ابتدا، مدلی که برای تولید embeddingها میخواهید استفاده کنید تعریف میشود. در این مثال، از مدل openai/text-embedding-ada-002 استفاده شده است.
در ادامه، یک تابع asynchronous به نام generateEmbeddings تعریف میشود. این تابع، دادهی ورودی (که در اینجا value نام دارد) را دریافت میکند و یک Promise از آرایهای از objectها را برمیگرداند. هر object شامل یک embedding و محتوای مربوط به آن است. درون این تابع، ابتدا ورودی به یکسری قطعه (chunk) تقسیم میشود. سپس این قطعهها به تابع embedMany، که از AI SDK وارد شده، ارسال میشوند؛ این تابع، embedding مربوط به هر chunk را تولید میکند. در نهایت، روی embeddingها پیمایش (map) انجام میشود تا خروجی نهایی در قالبی آماده برای ذخیرهسازی در دیتابیس، تولید شود.
بهروزرسانی Server Action
فایل lib/actions/resources.ts را باز کنید. این فایل حاوی تنها یک تابع به نام createResource است که همانطور که از نامش پیداست، برای ایجاد یک resource جدید مورد استفاده قرار میگیرد.
تابع تعریفشده در قطعه کد فوق، یک Server Action محسوب میشود، که با دستور ;'use server' در ابتدای فایل مشخص شده است. به همین دلیل، این تابع را میتوان از هر نقطهای در برنامهی Next.js فراخوانی کرد. عملکرد این تابع به این صورت است که یک ورودی دریافت میکند، آن را با استفاده از یک اسکیمای Zod اعتبارسنجی میکند تا اطمینان حاصل شود که ساختار ورودی مطابق با استاندارد مورد انتظار است، در نهایت، یک resource جدید در دیتابیس ایجاد میکند.
این نقطه، مکان مناسبی است تا embedding مربوط به resourceهای جدید نیز در همین مرحله، تولید و ذخیره شوند. به عبارت دیگر، پس از ایجاد resource و پیش از ذخیرهسازی نهایی در دیتابیس، میتوانید در همین تابع، از مدل بردارساز استفاده کرده و خروجی آن را به همراه سایر دادهها نگهداری کنید.
فایل را با قطعه کد زیر، آپدیت کنید:
در قطعه کد فوق، ابتدا، تابع generateEmbeddings که در مرحلهی قبل ایجاد کردهاید؛ فراخوانی میشود و محتوای منبع (content)، به آن داده میشود. پس از آنکه embeddingها متن را دریافت کردند (که در اینجا با e نشان داده شدهاند)، در دیتابیس ذخیره میشوند؛ بهطوری که هر embedding در کنار resourceId مرتبط با خودش، ذخیره میشود.
ایجاد صفحهی اصلی
بیایید رابط کاربری (Frontend) را بسازیم. هوک useChat در AI SDK این امکان را میدهد که بهسادگی یک رابط کاربری محاورهای برای برنامهی چتبات خود ایجاد کنید. در مسیر app/page.tsx، قطعه کد زیر را قرار دهید:
هوک useChat امکان استریم پیامهای چت از مدل را فراهم میکند، وضعیت ورودی چت را مدیریت کرده و هنگام دریافت پیامهای جدید، رابط کاربری را بهطور خودکار بهروزرسانی میکند.
برای اجرای سرور در حالت development، دستور زیر را اجرا کنید:
به آدرس http://localhost:3000 بروید. باید صفحهای خالی با یک نوار ورودی که در پایین صفحه قرار دارد، مشاهده کنید. سعی کنید یک پیام ارسال کنید. پیام برای کسری از ثانیه در رابط کاربری نمایش داده میشود و سپس ناپدید میشود. دلیل این اتفاق این است که هنوز مسیر API را برای فراخوانی مدل، تنظیم نکردهاید! بهطور پیشفرض، useChat یک درخواست POST به مسیر api/chat/ ارسال میکند و پیامها را بهعنوان request body منتقل مینماید.
میتوانید endpoint را در پیکربندی useChat سفارشیسازی کنید.
ایجاد مسیر API
در NextJS، میتوانید برای یک مسیر مشخص، request handler سفارشی ایجاد کنید. این کار با استفاده از Route Handlers انجام میشود. هندلرها در یک فایل route.ts تعریف میشوند و میتوانند متدهای HTTP مانند GET، POST، PUT، PATCH و ... را export کنند. برای ایجاد مسیر api/chat/، فایل app/api/chat/route.ts را ایجاد کرده و قطعه کد زیر را درون آن، قرار دهید:
در این کد، شما یک تابع asynchronous به نام POST تعریف و export میکنید. سپس پیامها را از request body بازیابی کرده و آنها را همراه با مدلی که قصد استفاده از آن را دارید، به تابع streamText که از AI SDK ایمپورت شده است، ارسال میکنید. در نهایت، پاسخ مدل را در قالب AIStreamResponse بازمیگردانید.
اکنون به مرورگر بازگردید و دوباره تلاش کنید پیامی ارسال کنید. باید پاسخ مدل را مشاهده کنید که بهطور مستقیم به صورت استریم برمیگردد!
ارتقای پرامپت
اکنون شما یک چتبات کاربردی دارید، اما هنوز کار خاص یا ویژهای انجام نمیدهد.
بیایید با افزودن system instructionها، رفتار مدل را اصلاح و محدود کنیم. در این حالت، شما میخواهید مدل تنها از اطلاعاتی که بازیابی کرده است برای تولید پاسخها استفاده کند. برای این کار، route handler خود را با کد زیر بهروزرسانی کنید:
اکنون به مرورگر بازگردید و از مدل بپرسید غذای موردعلاقهی شما چیست. از آنجا که مدل هیچ اطلاعات مرتبطی در اختیار ندارد، باید دقیقاً همانطور که در بالا دستور دادهاید پاسخ دهد (“Sorry, I don’t know”). در شکل کنونی، چتبات شما عملاً بیاستفاده است. پس چگونه میتوان به مدل توانایی افزودن و پرسوجوی (query) اطلاعات را داد؟
استفاده از toolها
tool یک تابع است که مدل میتواند برای انجام یک کار مشخص آن را فراخوانی کند. میتوانید tool را مانند یک برنامه در نظر بگیرید که آن را در اختیار مدل قرار میدهید تا هر زمان که لازم بداند آن را اجرا کند. بیایید ببینیم چگونه میتوانید یک tool ایجاد کنید که به مدل اجازه بدهد یک resource را ایجاد و embed کرده و در knowledge base چتبات، ذخیره کند.
افزودن resource tool
route handler خود را با کد زیر بهروزرسانی کنید:
در این کد، شما یک tool به نام addResource تعریف میکنید. این tool سه مؤلفه دارد:
- description: توضیحی از tool که تعیین میکند چه زمانی tool انتخاب شود
- parameters: یک Zod schema که پارامترهای لازم برای اجرای tool را تعریف میکند
- execute: یک تابع asynchronous که با آرگومانهای ارسالشده توسط فراخوانی tool اجرا میشود
به زبان ساده، در هر بار تولید پاسخ، مدل تصمیم میگیرد آیا باید tool را فراخوانی کند یا خیر. اگر مدل تصمیم بگیرد tool را فراخوانی کند، پارامترها را از ورودی استخراج کرده و یک پیام جدید از نوع tool-call به آرایهی messages اضافه میکند. سپس AI SDK تابع execute را با پارامترهای ارائهشده توسط پیام tool-call اجرا میکند.
اکنون به مرورگر بازگردید و به مدل بگویید که غذای مورد علاقهتان چیست. باید یک پاسخ خالی در رابط کاربری مشاهده کنید. آیا اتفاقی افتاد؟ بیایید بررسی کنیم. دستور زیر را در یک ترمینال جدید اجرا کنید:
دستور فوق، Drizzle Studio را راهاندازی میکند، جایی که میتوانید ردیفهای موجود در دیتابیسی خود را مشاهده کنید. باید یک ردیف جدید هم در جدول embeddings و هم در جدول resources مربوط به غذای مورد علاقهی خود، مشاهده کنید!
حال بیایید چند تغییر در رابط کاربری ایجاد کنیم تا به کاربر نشان دهیم زمانی که یک tool فراخوانی شده است. به صفحهی root خود بازگردید (app/page.tsx) و کد زیر را به آن، اضافه کنید:
با این تغییر، اکنون میتوانید آن tool که فراخوانی شده است را بهصورت شرطی مستقیماً در رابط کاربری (UI) نمایش دهید. فایل را ذخیره کنید و به مرورگر بازگردید. به مدل بگویید که فیلم مورد علاقهی شما چیست. اکنون باید به جای پاسخ متنی معمول مدل، ببینید که کدام tool فراخوانی شده است.
بهبود UX با فراخوانیهای چندمرحلهای
خوب است اگر مدل بتواند action انجامشده را نیز خلاصه کند. با این حال، از نظر فنی، هنگامی که مدل یک tool را فراخوانی میکند، تولید پاسخ خود را به پایان رسانده است، زیرا یک tool call ایجاد کرده است. پس چگونه میتوان این رفتار موردنظر را به دست آورد؟
AI SDK یک ویژگی به نام maxSteps دارد که نتایج فراخوانی tool را بهصورت خودکار به مدل بازمیگرداند.
app/page.tsx را باز کنید و قطعه کد زیر را جایگزین کد فعلی خود کنید:
به مرورگر بازگردید و به مدل بگویید تاپینگ پیتزای مورد علاقهی شما چیست. اکنون باید یک پاسخ follow-up از مدل مشاهده کنید که انجام عملیات را تأیید میکند.
tool بازیابی resource
مدل اکنون میتواند اطلاعات دلخواه را به knowledge base شما اضافه و embed کند، اما هنوز قادر به query کردن آن نیست. بیایید یک tool جدید ایجاد کنیم تا مدل بتواند با یافتن اطلاعات مرتبط در knowledge base، به سؤالات پاسخ دهد. برنامه، برای یافتن محتوای مشابه، باید ابتدا پرسش کاربر را embed کرده، سپس دیتابیس را برای شباهتهای معنایی (semantic similarities) جستجو کند و آن را بهعنوان context همراه با پرسش به مدل ارسال کند. برای انجام این کار، فایل lib/ai/embedding.ts را بهروزرسانی کنید:
در این کد، شما دو تابع اضافه میکنید:
- generateEmbedding: یک embedding واحد از یک ورودی تولید میکند
- findRelevantContent: پرسش کاربر را embed کرده، پایگاه داده را برای آیتمهای مشابه جستجو میکند و در نهایت آیتمهای مرتبط را بازمیگرداند
پس از انجام کار فوق، به مرحلهی نهایی میرسیم: ایجاد tool.
به api/chat/route.ts بازگردید و یک tool جدید به نام getInformation اضافه کنید:
به مرورگر بازگردید، صفحه را refresh کنید و غذای مورد علاقهی خود را بپرسید. اکنون باید ببینید که مدل getInformation را فراخوانی میکند و سپس از اطلاعات مرتبط برای ساخت پاسخ استفاده میکند.
نتیجهگیری
تبریک میگوییم! شما با موفقیت یک چتبات هوش مصنوعی ساختید که میتواند بهصورت پویا اطلاعات را به knowledge base اضافه کرده و از آن، اطلاعات را بازیابی کند. در طول این راهنما، شما یاد گرفتید چگونه embedding ایجاد و ذخیره کنید، server actionها را برای مدیریت منابع تنظیم کنید و از toolها برای گسترش قابلیتهای چتبات خود استفاده کنید.
پروژه کامل را میتوانید در گیتهاب لیارا مشاهده بفرمایید.